This week in AI: Billion-dollar valuations, and a power crisis no one saw coming
India’s AI ambitions have a power problem.
The country wants $200 billion in data centre and AI infrastructure investments by 2030. Microsoft, Amazon, Alphabet, Adani, Reliance—the commitments are already in.
Capacity is set to jump from 1.2GW today to 10GW by the end of the decade. On paper, it reads like a triumph of industrial policy.
But this week, India’s apex power planning body—the Central Electricity Authority—went back to the drawing board. The concern: A concentration of massive data centre hubs coming up in Andhra Pradesh, Karnataka, Maharashtra, Telangana and a handful of other states could skew electricity consumption so dramatically that it destabilises the national grid. Each data centre cluster could draw around 2GW of power continuously, enough to fundamentally alter the demand profile of an entire state. For Maharashtra or Karnataka, adding 2-3GW to the base load isn’t a rounding error. It’s a grid event.
The CEA is now asking states and power distribution companies to bake data centre demand into their resource adequacy plans—essentially, India is realising that the AI boom it has been so aggressively courting comes with an electricity bill nobody fully planned for.
It’s a reminder that behind every AI model, every GPU cluster, every sovereign cloud ambition, there is a very physical, very finite resource being consumed at scale. India is building for an AI future. It just needs to make sure the lights stay on. Here’s the rest of the week in AI:
DeepSeek has been accused of attempting to distill its models through “new, obfuscated methods”.
Photo by Mladen Antonov / AFPA
Rivals Unite Against China’s AI Copycat Machine
In what may be the most unexpected alliance in tech this year, OpenAI, Anthropic and Google—three companies locked in fierce competition for enterprise contracts and talent—announced they are pooling threat intelligence to combat a practice called adversarial distillation: The systematic extraction of capabilities from frontier AI models by feeding them millions of carefully crafted queries and using the responses to train cheaper, faster imitations.
The coordination is happening through the Frontier Model Forum, an industry non-profit the three companies co-founded with Microsoft in 2023, which until now had functioned largely as a venue for safety pledges and government-facing commitments. This week marked the first time it has been activated as an active threat-detection operation against named external adversaries.
The scale of the problem is striking. News reports state that Anthropic traced over 16 million unauthorised exchanges back to roughly 24,000 fraudulent accounts, with three Chinese firms—DeepSeek, Moonshot AI and MiniMax—identified by name. OpenAI has separately accused DeepSeek of attempting to distil its models through “new, obfuscated methods” and has formally flagged the issue to the House Select Committee on China.
That three direct competitors are voluntarily sharing attack pattern data tells you something about how seriously they view the threat. The deeper concern isn’t lost revenue—it’s safety.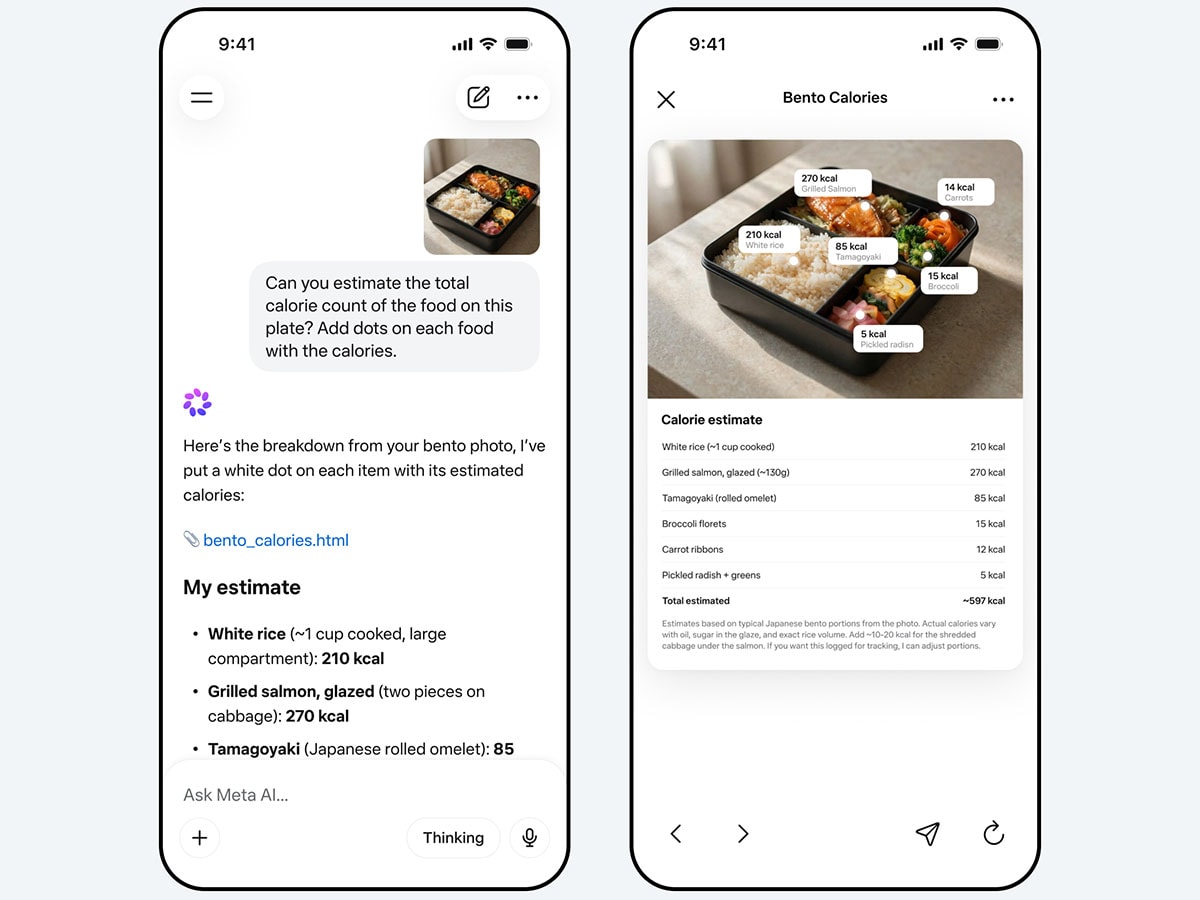
Meta’s most serious attempt yet to close the gap with OpenAI and Anthropic.
Photo courtesy Meta Ai
Meta’s $14 Billion Moment of Truth
Nine months after Mark Zuckerberg restructured his entire AI operation—pouring $14.3 billion into data labelling firm Scale AI and handing its co-founder Alexandr Wang the keys to a new unit called Meta Superintelligence Labs—its first product is here. Muse Spark, built from scratch in under a year, is Meta’s most serious attempt yet to close the gap with OpenAI and Anthropic.
The model is already live across Meta AI and Meta.ai, with a rollout to Facebook, Instagram and WhatsApp to follow. It handles voice, text and image inputs, has dedicated reasoning modes, and includes a shopping mode that draws on Meta’s vast trove of user behaviour data—a differentiator none of its rivals can easily replicate.
Meta is candid about where it falls short: coding remains a weak spot relative to the competition. But on multimodal understanding and health-related queries, the company says Muse Spark holds its own.
Anthropic is essentially saying Mythos is too capable to release openly, at least for now, and the responsible first use is defensive.
Photo courtesy Anthropic ai
Anthropic’s Most Powerful Model Is One You Can’t Use
Anthropic this week confirmed the existence of Claude Mythos—described internally as the most capable model the company has ever built. The catch: It won’t be publicly available. Only 50 organisations have been granted access, under a programme called ‘Project Glasswing’, and their job isn’t to build products with it. It’s to use Mythos to scan their own infrastructure for vulnerabilities before bad actors can exploit what the model is capable of.
The logic is deliberately paradoxical—deploy the most powerful AI to defend against the most powerful AI. Anthropic is essentially saying Mythos is too capable to release openly, at least for now, and the responsible first use is defensive.
The pricing signals ambition: $25 per million input tokens and $125 per million output tokens—significantly above current frontier rates. Anthropic has indicated access will eventually widen, but only once efficiency improvements make it commercially viable at scale.
What makes this notable isn’t just the capability claim. It’s the posture. At a moment when every other lab is racing to put their best model in front of as many users as possible, Anthropic locked its best work behind a 50-company firewall and called it a safety decision.
Pratyush Kumar and Vivek Raghavan, Co-Founders, Sarvam AI. Photo by Selvaprakash Lakshmanan for Forbes India
India’s Own AI Lab Is Having Its Moment
Bengaluru-based Sarvam AI is in advanced talks to raise $300–350 million at a valuation of $1.5–1.55 billion, with Bessemer Venture Partners leading and Nvidia, Amazon and Prosperity7 Ventures participating. If it closes, it would be the largest funding round for a pure-play Indian AI company to date.
Founded in 2023 by researchers Vivek Raghavan and Pratyush Kumar, Sarvam builds voice-first, agentic AI models across 22 Indian languages—a deliberate bet that the next billion AI users won’t interact in English. At February’s India AI Impact Summit, it unveiled two large language models trained entirely in India, with 30 billion and 105 billion parameters. Kumar’s line from the stage said it all: “Today we show we can bring our own AI to a billion Indians.”
Nvidia and Amazon’s participation isn’t just financial validation—it signals that the world’s most important AI infrastructure players are taking India’s homegrown bet seriously.
Rocket—the AI app-building platform launched Rocket 1.0 this week, pitching itself as the world’s first “Vibe Solutioning” platform. Photo courtesy Rocket
Rocket 1.0: Vibe Coding Grew Up
Surat-based Rocket—the AI app-building platform used by 1.5 million people across 180 countries—launched Rocket 1.0 this week, pitching itself as the world’s first “Vibe Solutioning” platform. The distinction matters. Where vibe coding tools like Emergent and Lovable answer the question of how to build, Rocket is trying to answer what to build—and what happens after you do.
The platform bundles three capabilities: Solve, which runs structured strategic research before a team commits to a product; Build, which turns that decision into a production-ready app; and Intelligence, which continuously monitors competitors across websites, reviews, job postings and marketing after launch.
Co-founder Vishal Virani puts it plainly: “The most expensive mistake in any business is good execution of the wrong thing.”
Seed-funded and backed by Salesforce Ventures and Accel, Rocket is one of India’s quieter but serious bets in the global vibe-coding race.